
剑指 Offer 12. 矩阵中的路径
题目描述
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
例如,在下面的 3×4 的矩阵中包含单词 "ABCCED"(单词中的字母已标出)。
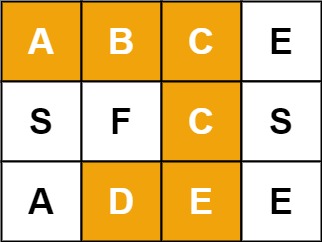
示例 1:
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED"
输出:true
示例 2:
输入:board = [["a","b"],["c","d"]], word = "abcd"
输出:false
提示:
1 <= board.length <= 200
1 <= board[i].length <= 200
board 和 word 仅由大小写英文字母组成
链接:https://leetcode-cn.com/problems/ju-zhen-zhong-de-lu-jing-lcof
注意:本题与主站 79 题相同:https://leetcode-cn.com/problems/word-search/
解题思路
DFS + 利用set剪枝,并定义一个self.sesult判断当前是不是已经出现了可行的路径。在本题中,需要试着用所有点为root开始dfs。
剪枝的概念:
1.在dfs的过程中,每个节点都可以往四个方向走(递归四次),所以建立个set防止走回头路(即如果(i, j) in set就return掉)。
2.有的路径本身val就是错的,直接return掉。
由于DFS使用了递归,需要注意时间复杂度。
注意:相邻节点包括上下左右。
解题代码
class Solution:
def dfs(self, used: set, i: int, j: int, path: str):
# 如果self.result已经为True那还遍历啥,直接返回,不然会导致超时
if i >= self.row_num or j >= self.col_num or i < 0 or j < 0 or (i, j) in used or self.result: # 边界条件和剪枝
return
c = self.board[i][j]
new_path = path + c
if new_path == self.word:
self.result = True
return
if new_path == self.word[:len(new_path)]:
# a-b-c-e
# s-f-e s
# a d e-e
# 匹配abceseeefs
# 这里需要建立一个新的set,不然会把c下面那个e废掉,使它不能以后路过
new_used = used.copy()
new_used.add((i, j))
self.dfs(new_used, i+1, j, new_path)
self.dfs(new_used, i-1, j, new_path)
self.dfs(new_used, i, j+1, new_path)
self.dfs(new_used, i, j-1, new_path)
def exist(self, board: list[list[str]], word: str) -> bool:
self.result = False
self.board = board
self.word = word
self.row_num, self.col_num = len(board), len(board[0])
for i in range(self.row_num):
for j in range(self.col_num): # 针对每个点开始尝试dfs
if board[i][j] == word[0] and not self.result:
used = set() # 每次dfs要使用新set
self.dfs(used, i, j, "")
return self.result
执行结果
执行结果:通过
执行用时:224 ms, 在所有 Python3 提交中击败了11.88%的用户
内存消耗:34.3 MB, 在所有 Python3 提交中击败了5.01%的用户
共有 0 条评论